
This chapter covers techniques and best practices for improving LLM reliability and performance in scenarios like complex reasoning and problem-solving. Adapting a model to a specific task—or ensuring its output matches expectations—is known as conditioning. We focus on two primary conditioning approaches: fine-tuning and prompting.
Fine-tuning trains a pre-trained model on task-specific data, enabling it to become more accurate and context-aware for a given application.
Prompting, by contrast, guides model behavior at inference time by supplying additional context or instructions. Prompt engineering plays a key role in unlocking LLM reasoning capabilities and provides a practical toolkit for researchers and practitioners. This chapter explores advanced techniques such as few-shot learning, tree-of-thought, and self-consistency.
Throughout the chapter, we apply both fine-tuning and prompting methods with LLMs.
Table of Contents
We begin by introducing conditioning, explaining why it matters and how it can be applied.
Conditioning LLMs
LLMs are pre-trained on diverse data, resulting in base models with broad language understanding. While models like GPT-4 can generate high-quality text across many topics, conditioning improves task relevance, specificity, coherence, and alignment with ethical and behavioral expectations. In this chapter, we focus on fine-tuning and prompting as primary conditioning methods.
Conditioning encompasses techniques used to steer model outputs, ranging from prompt design at inference time to more persistent approaches like fine-tuning on domain-specific datasets. These methods adapt a model’s responses to particular tasks, topics, or styles.
Effective conditioning enables LLMs to follow complex instructions and deliver outputs that closely match user expectations. It spans casual interactions as well as systematic training for specialized domains such as legal analysis or technical documentation. Conditioning also includes safeguards—such as filters or targeted training—to reduce harmful or malicious outputs and support ethical use.
Alignment, while related, is distinct from conditioning. Alignment focuses on ensuring a model’s overall behavior and decision-making conform to human values, ethics, and safety standards. Conditioning influences behavior through specific techniques, whereas alignment addresses broader, foundational goals.
Conditioning can occur at multiple stages of a model’s lifecycle. Models can be fine-tuned on task-specific data to specialize for a given use case, or dynamically conditioned at inference time through carefully crafted prompts. Fine-tuning offers persistence and specialization, while prompt-based conditioning provides flexibility but can add runtime complexity.
The next section summarizes key conditioning methods—fine-tuning and prompt engineering—explaining their motivations and comparing their strengths and limitations.
Methods for Conditioning
The rise of large pre-trained models such as GPT-3 has driven strong interest in techniques for adapting LLMs to downstream tasks. As these models evolve, advances in fine-tuning and prompting are enabling stronger reasoning, tool use, and broader applicability.
Several conditioning approaches exist across the model lifecycle. Table 1 summarizes the main techniques.
| Stage | Technique | Examples |
|---|---|---|
| Training | Data curation | Training on diverse data |
| Objective function | Careful design of training objective | |
| Architecture and training process | Optimizing model structure and training | |
| Fine-tuning | Task specialization | Training on specific datasets/tasks |
| Inference-time conditioning | Dynamic inputs | Prefixes, control codes, context examples |
| Human oversight | Human-in-the-loop | Human review and feedback |
Combining these techniques gives developers greater control over model behavior and outputs. The overarching goal is to incorporate human values throughout training and deployment to produce responsible and aligned AI systems.
This chapter focuses on fine-tuning and prompting, as they are the most widely used and effective conditioning methods.
Fine-tuning
Fine-tuning updates a pre-trained model’s parameters using task-specific data to improve performance on targeted objectives. While effective, it is often computationally expensive. To reduce costs, Parameter-Efficient Fine-Tuning (PEFT) methods—such as adapters and Low-Rank Adaptation (LoRA)—train only a small subset of parameters while freezing the base model.
LoRA injects trainable low-rank matrices into Transformer layers, achieving performance comparable to full fine-tuning with fewer parameters and higher throughput. QLoRA extends this approach by fine-tuning low-rank adapters on a frozen 4-bit quantized model, enabling fine-tuning of models as large as 65B parameters on a single GPU while retaining near-ChatGPT performance.
Closely related is quantization, which reduces numerical precision to lower memory and compute costs. LLMs commonly operate well at 4–8-bit precision, especially when combined with fine-tuning or quantization-aware training.
Reinforcement Learning with Human Feedback (RLHF)
RLHF has played a transformative role in modern LLMs. In 2022, OpenAI demonstrated that RLHF combined with Proximal Policy Optimization (PPO) significantly improved GPT-3 alignment with human preferences.
RLHF consists of three stages:
- Supervised pre-training on human demonstrations
- Reward model training using human rankings of outputs
- Reinforcement learning to maximize the learned reward
This approach enabled InstructGPT, which outperformed GPT-3 on user preference, truthfulness, and harm reduction despite having far fewer parameters. RLHF’s success influenced subsequent models, including GPT-3.5, while also motivating research into making RL training more stable and data-efficient.
Inference-time conditioning
In many cases, conditioning at inference time is preferable to fine-tuning, especially when:
- Fine-tuning is unavailable or restricted (API-based models)
- Task-specific data is limited
- Data changes frequently
- Applications require per-user or contextual adaptation
Inference-time conditioning typically uses prompts or constraints supplied during generation. Common techniques include:
- Prompt tuning: Natural-language instructions
- Prefix tuning: Trainable vectors prepended to model layers
- Token constraints: Forcing or banning specific tokens
- Metadata conditioning: Providing genre, audience, or style hints
Prompts can include instructions, demonstrations, retrieved documents, or user-specific context. Zero-shot prompting uses no examples, while few-shot prompting includes a small number of solved examples to induce desired behavior. Large frozen models like GPT-3 and GPT-4 can often solve new tasks using prompting alone.
Inference-time conditioning may also occur during sampling, such as grammar-based constraints that enforce structured outputs (for example, valid code or JSON).
Prompting offers low-overhead control and rapid adaptation, but effective results require careful prompt engineering—an area explored further in this chapter.
In the next section, we fine-tune a small open-source LLM (OpenLLaMa) for question answering using PEFT and quantization, and deploy it on Hugging Face.
Fine-tuning
As discussed earlier, the goal of fine-tuning LLMs is to adapt a general-purpose foundation model to generate task- and context-specific outputs. Pre-trained language models capture broad linguistic knowledge but are not optimized for specific downstream tasks until they are adapted.
Fine-tuning updates a model’s pre-trained weights using task-specific datasets and objectives, enabling effective knowledge transfer while customizing behavior for specialized use cases.
Key advantages of fine-tuning include:
- Steerability: Improved instruction following through instruction tuning
- Reliable output formatting: Critical for structured outputs such as API or function calls
- Custom tone and style: Adapting responses to specific audiences or domains
- Alignment: Encouraging outputs that reflect safety, security, and privacy values
Fine-tuning has its roots in early computer vision research and became standard in NLP with models such as ULMFiT, ELMo, and later BERT, which established transformer fine-tuning as the dominant paradigm.
In this section, we fine-tune an LLM for question answering. While the approach is framework-agnostic, we note where LangChain integrations may be useful.
Setup for Fine-tuning
Fine-tuning delivers strong results but is computationally demanding, so we run experiments on Google Colab, which provides free access to GPUs and TPUs. For this example, the free tier is sufficient.
Access Colab here.
Make sure to set the runtime to GPU or TPU. We install the required libraries with fixed versions to ensure reproducibility:
peft(0.5.0) – parameter-efficient fine-tuningtrl(0.6.0) – reinforcement learning utilitiesbitsandbytes(0.41.1) – k-bit optimization and quantizationaccelerate(0.22.0) – multi-GPU and mixed-precision trainingtransformers(4.32.0) – Hugging Face Transformersdatasets(2.14.4) – dataset loading and processingsentencepiece(0.1.99) – tokenizationwandb(0.15.8) – experiment trackinglangchain(0.0.273) – loading the trained model as a LangChain LLM
!pip install -U accelerate bitsandbytes datasets transformers peft trl sentencepiece wandb langchain huggingface_hub
To download and optionally publish models, authenticate with Hugging Face. If you plan to upload models, generate a token with write permissions:
Authenticate directly from the notebook:
from huggingface_hub import notebook_login
notebook_login()
Experiment Tracking with Weights & Biases
We use Weights & Biases (W&B) to monitor training progress. Set the project name:
import os
os.environ["WANDB_PROJECT"] = "finetuning"
Create a free account at https://www.wandb.ai and obtain an API key from:
https://wandb.ai/authorize
If a previous run is active, close it before starting:
import wandb
if wandb.run is not None:
wandb.finish()
Dataset Selection
Fine-tuning can target many tasks—coding, reasoning, math, storytelling, or tool use—using datasets from Hugging Face:
https://huggingface.co/datasets
Custom datasets can also be created, for example using LangChain for data generation and filtering, though full data collection pipelines are outside the scope of this chapter.
For this recipe, we fine-tune on SQuAD v2, a question-answering dataset:
from datasets import load_dataset
dataset_name = "squad_v2"
dataset = load_dataset(dataset_name, split="train")
eval_dataset = load_dataset(dataset_name, split="validation")
SQuAD v2 provides predefined training and validation splits, which we use for early stopping to prevent overfitting.
Dataset structure:
DatasetDict({
train: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 130319
}),
validation: Dataset({
features: ['id', 'title', 'context', 'question', 'answers'],
num_rows: 11873
})
})
Each example includes a context passage, a question, and one or more possible answers. During training, the model is prompted with a question and evaluated against the ground-truth answers.
In the next section, we use this setup to fine-tune an open-source LLM using PEFT and quantization techniques.
Open-source models
For local experimentation, we want a small, efficient model that runs at a reasonable token rate. While LLaMA-2 models require accepting a license (with some commercial restrictions), open derivatives such as OpenLLaMa perform well and rank competitively on the Hugging Face leaderboard:
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
OpenLLaMa v1 is unsuitable for coding tasks due to tokenizer limitations, so we use OpenLLaMa v2. A 3B-parameter variant strikes a good balance between performance and hardware requirements:
model_id = "openlm-research/open_llama_3b_v2"
new_model_name = f"openllama-3b-peft-{dataset_name}"
Even smaller models (for example, EleutherAI/gpt-neo-125m) can also be viable when resources are constrained.
Loading the model with quantization
We load the model using 4-bit quantization via BitsAndBytes to reduce memory usage while maintaining performance:
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
base_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
base_model.config.use_cache = False
BitsAndBytes supports 8-, 4-, 3-, and even 2-bit quantization, significantly reducing memory footprint and improving inference speed with minimal accuracy loss.
Storing checkpoints on Google Drive
We save model checkpoints to Google Drive:
from google.colab import drive
drive.mount('/content/gdrive')
Set the output directory:
output_dir = "/content/gdrive/My Drive/results"
(Alternatively, use any local directory.)
Tokenizer setup
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
Training configuration with LoRA
We configure LoRA-based PEFT and standard training arguments:
from transformers import TrainingArguments, EarlyStoppingCallback
from peft import LoraConfig
base_model.config.pretraining_tp = 1
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
training_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=10,
max_steps=2000,
num_train_epochs=100,
evaluation_strategy="steps",
eval_steps=5,
save_total_limit=5,
push_to_hub=False,
load_best_model_at_end=True,
report_to="wandb",
)
Key notes:
push_to_hub: enables automatic uploads to Hugging Face if authenticated- High
max_stepsandnum_train_epochsallow continued improvement - Early stopping requires step-based evaluation
- Training metrics are logged to Weights & Biases
Training the model
We use SFTTrainer for supervised fine-tuning:
from trl import SFTTrainer
trainer = SFTTrainer(
model=base_model,
train_dataset=dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
dataset_text_field="question", # dataset-dependent
max_seq_length=512,
tokenizer=tokenizer,
args=training_args,
callbacks=[EarlyStoppingCallback(early_stopping_patience=200)],
)
trainer.train()
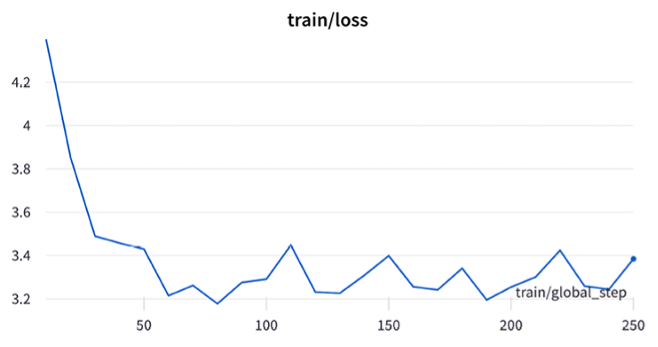
Training can take significant time, especially with frequent evaluation. Disabling early stopping can speed things up.
Training progress is best visualized in W&B.
Saving and publishing the model
Save the final checkpoint locally:
trainer.model.save_pretrained(
os.path.join(output_dir, "final_checkpoint")
)
Optionally, push the adapter to Hugging Face:
trainer.model.push_to_hub(
repo_id=new_model_name
)
Loading the model with LangChain
PEFT models are stored as adapters, so loading differs slightly:
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from langchain.llms import HuggingFacePipeline
model_id = "openlm-research/open_llama_3b_v2"
config = PeftConfig.from_pretrained(
"benji1a/openllama-3b-peft-squad_v2"
)
model = AutoModelForCausalLM.from_pretrained(model_id)
model = PeftModel.from_pretrained(
model,
"benji1a/openllama-3b-peft-squad_v2"
)
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=256,
)
llm = HuggingFacePipeline(pipeline=pipe)
Although this workflow is demonstrated on Google Colab, it can also be executed locally—just ensure the peft library is installed.
Commercial models
So far, we’ve focused on fine-tuning and deploying open-source LLMs. Some commercial models also support fine-tuning on custom data, including OpenAI’s GPT-3.5 and Google’s PaLM models. These capabilities are accessible through several Python libraries.
One lightweight option is Scikit-LLM, which abstracts cloud-based fine-tuning into a few lines of code. We won’t walk through a full setup here, but you can refer to the Scikit-LLM documentation or individual cloud providers for details. Note that Scikit-LLM is not included in the LangChain setup from Chapter 3 and must be installed separately. You’ll also need to supply your own training data (X_train, y_train).
Fine-tuning PaLM for text classification
from skllm.models.palm import PaLMClassifier
clf = PaLMClassifier(n_update_steps=100)
clf.fit(X_train, y_train) # y_train is a list of labels
labels = clf.predict(X_test)
Fine-tuning GPT-3.5 for text classification
from skllm.models.gpt import GPTClassifier
clf = GPTClassifier(
base_model="gpt-3.5-turbo-0613",
n_epochs=None, # Automatically determined by OpenAI
default_label="Random" # Optional
)
clf.fit(X_train, y_train) # y_train is a list of labels
labels = clf.predict(X_test)
OpenAI’s fine-tuning pipeline automatically passes all inputs through a moderation system to ensure compliance with safety standards.
This concludes our discussion of fine-tuning. While fine-tuning can significantly improve task performance, LLMs can often be used effectively without it. In the next section, we explore prompting techniques, including zero-shot and few-shot learning.
Commercial models
So far, we’ve focused on fine-tuning and deploying open-source LLMs. Some commercial models also support fine-tuning on custom data, including OpenAI’s GPT-3.5 and Google’s PaLM models. These capabilities are accessible through several Python libraries.
One lightweight option is Scikit-LLM, which abstracts cloud-based fine-tuning into a few lines of code. We won’t walk through a full setup here, but you can refer to the Scikit-LLM documentation or individual cloud providers for details. Note that Scikit-LLM is not included in the LangChain setup from Chapter 3 and must be installed separately. You’ll also need to supply your own training data (X_train, y_train).
Fine-tuning PaLM for text classification
from skllm.models.palm import PaLMClassifier
clf = PaLMClassifier(n_update_steps=100)
clf.fit(X_train, y_train) # y_train is a list of labels
labels = clf.predict(X_test)
Fine-tuning GPT-3.5 for text classification
from skllm.models.gpt import GPTClassifier
clf = GPTClassifier(
base_model="gpt-3.5-turbo-0613",
n_epochs=None, # Automatically determined by OpenAI
default_label="Random" # Optional
)
clf.fit(X_train, y_train) # y_train is a list of labels
labels = clf.predict(X_test)
OpenAI’s fine-tuning pipeline automatically passes all inputs through a moderation system to ensure compliance with safety standards.
This concludes our discussion of fine-tuning. While fine-tuning can significantly improve task performance, LLMs can often be used effectively without it. In the next section, we explore prompting techniques, including zero-shot and few-shot learning.
Prompt engineering
Prompts are the instructions and examples provided to language models to guide their behavior. They play a central role in aligning model outputs with human intent without expensive retraining, enabling LLMs to perform tasks far beyond their original training scope. Well-designed prompts act as explicit demonstrations of the desired input–output mapping.
A prompt typically consists of three components:
- Instructions: Clear task descriptions, goals, and output formats
- Examples: Input–output demonstrations that show the desired behavior
- Input: The specific data the model must act on
Figure 3 illustrates several prompting examples, including closed-form knowledge probing and summarization (from Pre-train, Prompt, and Predict by Liu et al., 2021).
Prompt engineering—also referred to as in-context learning—steers model behavior through carefully crafted prompts without modifying model weights. While prompt tuning offers flexible control, it is sensitive to wording and structure, making prompt design a critical skill.
A practical approach is to start simple and iterate. Begin with concise, direct instructions and gradually add complexity. Break complex tasks into smaller sub-tasks, specify output formats clearly, and include relevant examples to demonstrate reasoning or style.
For tasks involving reasoning, prompting models to explain their steps improves accuracy. Techniques such as chain-of-thought prompting, few-shot examples, and problem decomposition encourage structured reasoning. Sampling multiple candidate outputs and selecting the most consistent response further reduces errors and variability.
Effective prompts focus on what to do, not what to avoid. Clear, specific, and unambiguous instructions outperform vague or restrictive ones. With careful iteration and experimentation, prompt engineering can deliver reliable performance—often rivaling fine-tuning—especially for complex tasks.
Next, we explore a range of prompt techniques, starting with simple methods and progressing to more advanced strategies.
Prompt techniques
Basic prompting methods include zero-shot prompting, which relies only on the input text, and few-shot prompting, which adds a small number of example input–output pairs. Few-shot performance can vary due to biases such as majority-label and recency bias, but careful example selection, ordering, and formatting can mitigate these effects.
More advanced techniques go beyond simple demonstrations. Instruction prompting explicitly describes task requirements, while self-consistency samples multiple outputs and selects the most consistent one. Chain-of-Thought (CoT) prompting encourages models to generate intermediate reasoning steps before producing a final answer, significantly improving performance on complex reasoning tasks. CoT reasoning can be written manually or generated automatically using methods such as augment–prune–select.
| Technique | Description | Key Idea | Performance Considerations |
|---|---|---|---|
| Zero-Shot Prompting | No examples provided | Leverages pre-training | Works for simple tasks |
| Few-Shot Prompting | Few demonstrations | Shows desired reasoning | Tripled GSM accuracy |
| Chain-of-Thought | Explicit reasoning steps | Think before answering | 4× math accuracy |
| Least-to-Most | Solve simpler subtasks first | Problem decomposition | Boosted accuracy to 99.7% |
| Self-Consistency | Select most frequent answer | Redundant sampling | +1–24 pts across tasks |
| Chain-of-Density | Iterative summary refinement | Dense summaries | Improves info density |
| Chain-of-Verification | Verifies responses via questions | Human-like checking | Higher robustness |
| Active Prompting | Human-labeled uncertain examples | Better few-shot demos | Improved accuracy |
| Tree-of-Thought | Explores reasoning branches | Backtracking | Optimal reasoning paths |
| Verifiers | Separate evaluation model | Filters bad answers | +20 pts GSM accuracy |
| Fine-Tuning | Train on explanation data | Improves reasoning | 73% commonsense QA |
Some prompting approaches incorporate retrieval to provide missing context before generation. For open-domain QA, relevant documents can be retrieved and prepended to the prompt. For closed-book QA, few-shot examples with evidence–question–answer formats tend to work better than plain QA prompts.
LangChain supports many of these techniques—including zero-shot, few-shot, CoT, self-consistency, and tree-of-thought—making it easier to apply advanced prompt strategies in practice.
We start with the simplest strategy: zero-shot prompting.
Zero-shot prompting
Zero-shot prompting provides task instructions without examples, testing the model’s ability to generalize from pre-training alone:
from langchain import PromptTemplate
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI()
prompt = PromptTemplate(
input_variables=["text"],
template="Classify the sentiment of this text: {text}"
)
chain = prompt | model
print(chain.invoke({
"text": "I hated that movie, it was terrible!"
}))
Output:
content='The sentiment of this text is negative.'
additional_kwargs={} example=False
Few-shot learning
Few-shot learning supplies a small number of examples to demonstrate the desired behavior. The model infers task intent from these demonstrations alone. While effective, few-shot prompting can be sensitive to example choice and ordering. Combining examples with clear instructions often improves robustness.
The FewShotPromptTemplate allows easy priming with demonstrations. Below, we classify customer feedback as Positive, Neutral, or Negative:
examples = [
{
"input": "I absolutely love the new update! Everything works seamlessly.",
"output": "Positive",
},
{
"input": "It's okay, but I think it could use more features.",
"output": "Neutral",
},
{
"input": "I'm disappointed with the service, I expected much better performance.",
"output": "Negative",
},
]
Construct the prompt:
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
from langchain.chat_models import ChatOpenAI
example_prompt = PromptTemplate(
template="{input} -> {output}",
input_variables=["input", "output"],
)
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"],
)
print((prompt | ChatOpenAI()).invoke({
"input": "This is an excellent book with high quality explanations."
}))
Expected output:
content='Positive'
additional_kwargs={} example=False
Few-shot prompting primes the model using context rather than training. For dynamic example selection, FewShotPromptTemplate can be combined with a SemanticSimilarityExampleSelector, which chooses examples based on embedding similarity rather than static lists.
While standard few-shot prompting works well for many tasks, more advanced techniques are often required for complex reasoning—topics we explore next.
Chain-of-Thought prompting
Chain-of-Thought (CoT) prompting encourages LLMs to reason explicitly by generating intermediate steps before producing a final answer. This is typically achieved by instructing the model to “think step by step.”
There are two main variants: zero-shot CoT and few-shot CoT.
Zero-shot Chain-of-Thought
In zero-shot CoT, we simply add a reasoning cue—such as “Let’s think step by step!”—to the prompt. This often improves performance on reasoning tasks by encouraging the model to logically derive the answer rather than guessing and post-justifying.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
reasoning_prompt = "{question}\nLet's think step by step!"
prompt = PromptTemplate(
template=reasoning_prompt,
input_variables=["question"]
)
model = ChatOpenAI()
chain = prompt | model
print(chain.invoke({
"question": "There were 5 apples originally. I ate 2 apples. My friend gave me 3 apples. How many apples do I have now?"
}))
Example output:
Step 1: Originally, there were 5 apples.
Step 2: I ate 2 apples.
Step 3: So, I had 5 - 2 = 3 apples left.
Step 4: My friend gave me 3 apples.
Step 5: Adding the apples my friend gave me, I now have 3 + 3 = 6 apples.
This approach is known as zero-shot chain-of-thought.
Few-shot Chain-of-Thought
Few-shot CoT extends standard few-shot prompting by including explicit reasoning in the example outputs. This demonstrates not only what the answer is, but how to arrive at it.
Extending our earlier sentiment classification examples:
examples = [
{
"input": "I absolutely love the new update! Everything works seamlessly.",
"output": "Love and works seamlessly indicate positive sentiment. Therefore, the sentiment is positive."
},
{
"input": "It's okay, but I think it could use more features.",
"output": "The phrase 'it's okay' is lukewarm, and the desire for improvements suggests neutrality. Therefore, the sentiment is neutral."
},
{
"input": "I'm disappointed with the service, I expected much better performance.",
"output": "The customer expresses disappointment and unmet expectations. This indicates negative sentiment."
}
]
By explicitly explaining the reasoning, we encourage the model to follow the same reasoning pattern in future responses.
Empirical studies show that CoT prompting significantly improves accuracy on complex reasoning tasks, especially for larger models. For smaller models, however, the gains may be marginal or even negative.
Self-consistency prompting
Self-consistency improves reliability by generating multiple candidate answers and selecting the most frequent or consistent one. This approach is particularly effective for factual questions and reasoning-heavy tasks.
Step 1: Generate multiple solutions
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
solutions_template = """
Generate {num_solutions} distinct answers to this question:
{question}
Solutions:
"""
solutions_prompt = PromptTemplate(
template=solutions_template,
input_variables=["question", "num_solutions"]
)
solutions_chain = LLMChain(
llm=ChatOpenAI(),
prompt=solutions_prompt,
output_key="solutions"
)
Step 2: Select the most frequent answer
consistency_template = """
For each answer in {solutions}, count how many times it appears.
Select the most frequent answer.
Most frequent solution:
"""
consistency_prompt = PromptTemplate(
template=consistency_template,
input_variables=["solutions"]
)
consistency_chain = LLMChain(
llm=ChatOpenAI(),
prompt=consistency_prompt,
output_key="best_solution"
)
Combine using a SequentialChain
from langchain.chains import SequentialChain
answer_chain = SequentialChain(
chains=[solutions_chain, consistency_chain],
input_variables=["question", "num_solutions"],
output_variables=["best_solution"]
)
print(answer_chain.run(
question="Which year was the Declaration of Independence of the United States signed?",
num_solutions="5"
))
Example output:
1776 is the year in which the Declaration of Independence of the United States was signed.
Even though several generated answers may be incorrect, selecting the most frequent response often yields the correct result, reducing the impact of outliers.
Tree-of-Thought prompting
Tree-of-Thought (ToT) prompting generalizes CoT by exploring multiple reasoning paths and evaluating them before selecting the best solution. This approach helps avoid dead ends by fostering structured exploration.
LangChain provides an experimental ToT implementation, but below is a step-by-step illustrative implementation using standard chains.
Step 1: Generate candidate solutions
solutions_template = """
Generate {num_solutions} distinct solutions for {problem}.
Consider factors such as {factors}.
Solutions:
"""
solutions_prompt = PromptTemplate(
template=solutions_template,
input_variables=["problem", "factors", "num_solutions"]
)
Step 2: Evaluate solutions
evaluation_template = """
Evaluate each solution in {solutions}.
Consider pros, cons, feasibility, and likelihood of success.
Evaluations:
"""
evaluation_prompt = PromptTemplate(
template=evaluation_template,
input_variables=["solutions"]
)
Step 3: Expand reasoning
reasoning_template = """
For the most promising solutions in {evaluations},
describe implementation strategies, partnerships, and potential obstacles.
Enhanced Reasoning:
"""
reasoning_prompt = PromptTemplate(
template=reasoning_template,
input_variables=["evaluations"]
)
Step 4: Rank solutions
ranking_template = """
Based on the evaluations and reasoning, rank the solutions in {enhanced_reasoning}
from most to least promising.
Ranked Solutions:
"""
ranking_prompt = PromptTemplate(
template=ranking_template,
input_variables=["enhanced_reasoning"]
)
Assemble the Tree-of-Thought chain
from langchain.chains.llm import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.chains import SequentialChain
solutions_chain = LLMChain(
llm=ChatOpenAI(),
prompt=solutions_prompt,
output_key="solutions"
)
evaluation_chain = LLMChain(
llm=ChatOpenAI(),
prompt=evaluation_prompt,
output_key="evaluations"
)
reasoning_chain = LLMChain(
llm=ChatOpenAI(),
prompt=reasoning_prompt,
output_key="enhanced_reasoning"
)
ranking_chain = LLMChain(
llm=ChatOpenAI(),
prompt=ranking_prompt,
output_key="ranked_solutions"
)
tot_chain = SequentialChain(
chains=[solutions_chain, evaluation_chain, reasoning_chain, ranking_chain],
input_variables=["problem", "factors", "num_solutions"],
output_variables=["ranked_solutions"]
)
print(tot_chain.run(
problem="Prompt engineering",
factors="High task performance, low token usage, and minimal LLM calls",
num_solutions=3
))
Example output:
1. Fine-tune or adapt language models using task-specific datasets.
2. Develop specialized reasoning algorithms to enhance model performance.
3. Evaluate existing models to identify strengths and weaknesses.
Summary
Conditioning enables developers to steer generative AI systems to improve performance, safety, and output quality. This chapter focused on two primary conditioning approaches: fine-tuning and prompting.
Fine-tuning adapts language models to specific tasks by training them on instruction–response examples, often using reinforcement learning with human feedback (RLHF). We also examined more resource-efficient alternatives that achieve competitive results. As a practical example, we fine-tuned a small open-source model for question answering.
Prompting provides a flexible, low-overhead way to improve reliability—especially for complex reasoning tasks. Techniques such as step-by-step reasoning, problem decomposition, self-consistency, verifier models, and structured exploration have been shown to boost accuracy and consistency. Using LangChain, we demonstrated advanced strategies including few-shot learning, Chain-of-Thought (CoT), and Tree-of-Thought (ToT).
In Chapter 9, Generative AI in Production, we turn to deploying LLM applications in real-world settings, covering evaluation, serving, and monitoring of generative AI systems.