
While this tutorial focuses on integrating generative AI—especially large language models (LLMs)—into software applications, this chapter zooms in on using LLMs for software development itself. This area has been identified by consultancies such as KPMG and McKinsey as one of the domains most impacted by generative AI.
We start by exploring how LLMs support coding tasks, reviewing key literature to assess progress toward automating parts of software engineering. We then cover recent advances and new models, followed by a qualitative evaluation of generated code. Next, we build a fully automated software-development agent, discussing its design and showing results from a minimal LangChain-based Python implementation. Finally, we outline possible extensions to this approach.
Table of Contents
The chapter opens with a high-level overview of the current state of the art in AI-driven software development.
Software development and AI
The rise of systems like ChatGPT has renewed interest in AI-assisted software development. A June 2023 KPMG report estimated that roughly 25% of software development tasks could be automated, while McKinsey identified the function as a major opportunity for cost reduction and efficiency gains through generative AI. Although the idea of using AI to support programming is not new, it has accelerated rapidly alongside advances in computing and machine learning.
Early efforts date back to the 1950s and 1960s, when language and compiler design aimed to make programming more accessible. FLOW-MATIC (1955), developed under Grace Hopper, generated code from English-like statements, while BASIC (1963) introduced an interpreted language designed for ease of use. Later, paradigms such as flow-based programming (FBP), introduced by J. Paul Morrison in the 1970s, modeled applications as networks of black-box processes communicating via messages. Visual low-code and no-code tools followed, including LabVIEW for engineering applications and KNIME for data science.
Attempts to automate coding with AI began in the 1980s with expert systems—rule-based, narrow AI approaches that encoded domain knowledge for tasks such as debugging. While effective in limited settings, they required extensive manual rule definition. In parallel, developer tools evolved from command-line editors (ed, vim, emacs) to modern IDEs like Visual Studio and PyCharm, offering navigation, refactoring, testing, and static analysis. Tools such as Lint (1978) flagged bugs and style issues early on, and over time, machine learning methods—including genetic programming and neural networks—were applied to code analysis. This chapter focuses on how far deep learning, especially transformer models, has taken these ideas.
Today, models can generate partial or complete programs from natural language descriptions or code context, powering coding assistants and completion systems.
Present day
Recent breakthroughs from DeepMind highlight AI’s growing role in foundational computing. AlphaTensor discovered optimized matrix multiplication algorithms, while AlphaDev uncovered faster sorting and hashing algorithms that were integrated into widely used C++ libraries, improving performance at scale. These results show how AI can outperform human-designed algorithms in low-level optimization tasks.
DeepMind’s AlphaCode (February 2022) demonstrated an AI system capable of generating competitive programming solutions at a level comparable to an average human programmer. Its approach relied on large-scale candidate generation followed by filtering. While influential, questions remain about its practicality and scalability.
Meanwhile, code-focused LLMs such as ChatGPT and GitHub Copilot have seen widespread adoption, delivering significant productivity gains. Common programming tasks addressed by these models include:
- Code completion – predicting the next code element from context, often within IDEs.
- Code summarization/documentation – generating natural language explanations of source code.
- Code search – retrieving relevant code snippets from natural language queries via joint embeddings.
- Bug finding and fixing – identifying and correcting errors or vulnerabilities through prompted analysis.
- Test generation – creating unit and other tests to improve code quality and maintainability.
Modern AI programming assistants combine interactive tooling with advanced natural language understanding, allowing developers to describe functionality or issues in plain English. While powerful, concerns remain around code quality, security, and over-reliance on automation, making human oversight essential.
Next, we examine the current performance of AI systems for coding, with a focus on code-oriented LLMs.
Code LLMs
A growing number of code-focused AI models now compete across different capabilities, each with distinct strengths and limitations. Table 1 summarizes several of the most widely used public chat interfaces for software development.
Model comparison
| Model | Reads files | Runs code | Tokens |
|---|---|---|---|
| ChatGPT (GPT-3.5/4) | No | No | up to 32k |
| ChatGPT (Code Interpreter) | Yes | Yes | up to 32k |
| Claude 2 | Yes | No | 100k |
| Bard | No | Yes | 1k |
| Bing | Yes | No | 32k |
This competitive landscape benefits users but also means that no single model is optimal for all tasks. Selecting the right model increasingly depends on the specific programming problem at hand.
Modern code LLMs leverage deep learning and large-scale pretraining to provide context-aware assistance. They support tasks such as code completion, bug detection, automated testing, and code search. Microsoft’s GitHub Copilot, powered by OpenAI’s Codex, suggests code in real time using patterns learned from public repositories. According to a GitHub report (June 2023), developers accepted Copilot’s suggestions roughly 30% of the time, with the largest productivity gains seen among less experienced programmers.
Codex, a GPT-3–derived model fine-tuned on large volumes of public GitHub code, was designed specifically for translating natural language into executable programs. To quantify progress in code generation, many studies rely on the HumanEval benchmark, introduced in the Codex paper (2021). HumanEval consists of 164 programming tasks where models must complete functions based on docstrings. Performance is typically measured using pass@k (often pass@1), indicating the fraction of correct solutions among generated samples.
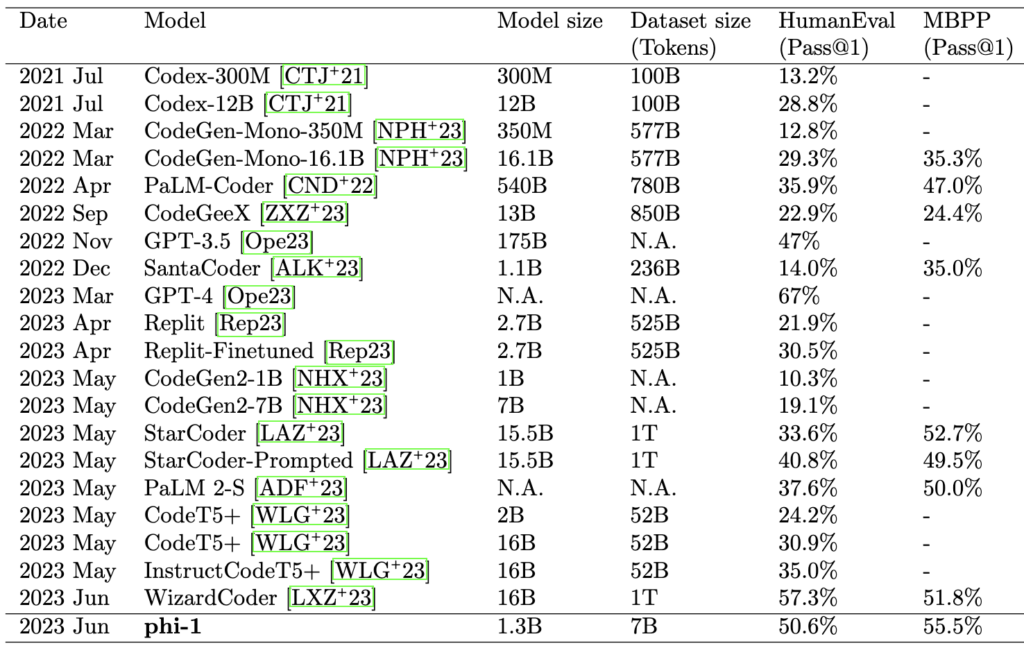
It is important to note that most LLMs are trained on datasets containing substantial amounts of source code. For example, The Pile includes roughly 11% GitHub code (over 100 GB) and has been used to train several prominent open models, including LLaMA and YaLM.
HumanEval is only one of many programming benchmarks. Figure 2 shows an example from an advanced computer science exam alongside Codex’s response, illustrating both the promise and limitations of current systems.

A broad body of research has examined AI-assisted programming across tasks such as code search, generation, summarization, debugging, testing, and reasoning.
Recent work has explored how LLMs support developers’ daily activities, introduced new code-specialized models (e.g., Codex, StarCoder, Phi-1), and proposed reasoning or planning strategies to improve performance. Notably, Textbooks Are All You Need (Gunasekar et al., 2023) introduced phi-1, a 1.3B-parameter transformer trained on carefully filtered, high-quality data. Despite its small size, phi-1 matches or exceeds models more than ten times larger on benchmarks such as HumanEval and MBPP, highlighting the importance of data quality over brute-force scaling.
Finally, while short code snippets often map directly from task descriptions to API calls, generating complete programs requires deeper reasoning, planning, and abstraction. Reasoning strategies can significantly improve performance even on small tasks. The Reflexion framework (Shinn et al., 2023) demonstrates this by enabling LLM agents to learn from verbalized trial-and-error feedback. Using episodic memory and self-reflection, Reflexion achieves a reported 91% pass@1 accuracy on HumanEval, surpassing previously published results, including GPT-4.
Outlook
Advances in multimodal AI are likely to further transform programming tools. Systems that jointly process code, documentation, images, and other inputs promise more natural and efficient developer workflows. The future of AI as a programming partner is promising, but depends on balancing human creativity with machine-driven productivity.
Realizing this potential requires deliberate integration. Establishing best practices—such as standardized prompts, pre-prompts, and validation workflows—will be critical. Embedding AI assistants directly into development environments, rather than relying on stand-alone browser tools, improves usability and adoption. When implemented thoughtfully, AI can automate repetitive tasks and free developers to focus on complex design and problem-solving.
Legal and ethical issues remain unresolved, particularly around pre-training on copyrighted data. Organizations such as the Free Software Foundation have raised concerns about tools like Copilot and Codex, questioning fair-use assumptions, the detectability of infringing code, and the copyright status of machine learning models themselves. Internal GitHub studies have shown that a small fraction of generated code contains verbatim excerpts from training data, sometimes with incorrect copyright notices. OpenAI has acknowledged this legal uncertainty, drawing comparisons to cases such as Authors Guild, Inc. v. Google, Inc.
From a practical standpoint, developers face trade-offs between convenience and control. Cloud-hosted AI services simplify adoption but may involve usage fees and data-ownership concerns. In contrast, open-source code LLMs offer transparency and are often trained on permissively licensed code, reducing legal risk while giving teams greater autonomy.
Beyond coding, these systems are reshaping the broader software ecosystem. The rise of ChatGPT coincided with a significant traffic decline on Stack Overflow, prompting the platform to introduce Overflow AI, which integrates conversational and semantic search over its knowledge base. Similar shifts are occurring across education and developer support communities.
Despite impressive progress, current LLMs excel mainly at common or well-specified problems. They struggle with novel tasks, long contexts, and dynamic program behavior. In education, they often outperform students on routine exercises but lack the robustness and reasoning needed to replace human programmers. Errors remain common, making expert oversight essential.
Overall, AI programming tools hold strong potential to boost developer productivity, but challenges in reliability, generalization, attention span, and semantic understanding persist. Continued research and careful deployment are necessary to ensure these systems remain transparent, trustworthy, and effective collaborators.
In the next section, we explore how to generate and execute software code with LLMs using LangChain.
Writing code with LLMs
We begin by using LLMs to generate code directly. Several public models support this task, including ChatGPT, Bard, and code-focused models accessible through LangChain. LangChain can call OpenAI models, PaLM’s code-bison, and open-source models via Replicate, HuggingFace Hub, or local runtimes such as Llama.cpp, GPT4All, and HuggingFace pipelines.
Code completion with StarCoder
As an example, we explore StarCoder using the HuggingFace Spaces playground.

StarCoder is not instruction-tuned, meaning it cannot follow commands like “write a class.” Instead, it performs text completion. Prompting it with a comment such as:
# dataclass of customer including an alphanumeric id, a name, and a birthday
produces a non-trivial Python dataclass implementation. After adding missing imports:
import re
from dataclasses import dataclass, field
the code executes without syntax errors. While impressive, closer inspection reveals several issues: missing docstrings, debugging print() statements, questionable defaults, arbitrary validation rules, incorrect string processing, and—most critically—attempts to mutate a frozen dataclass. The output provides useful structure and ideas, but it is not production-ready.
Improving prompts
Using a more realistic prompt—a module-level docstring—produces better results:
"""Customer data model.
Here we implement our data model for customers, a dataclass with
fields firstname, lastname, customer_id (a hash).
"""
The generated code correctly hashes customer IDs and includes comparison logic, but still suffers from missing imports and illegal mutation of frozen attributes. After fixing these issues and correcting naming errors, the class becomes usable. This version is available as customer2.py in the repository. Overall, LLMs already provide value for generating boilerplate, even if human correction remains essential.
Instruction-tuned models: StarChat
To issue direct tasks, we switch to instruction-tuned models such as StarChat, based on StarCoder.

For a standard introductory computer science task, StarChat generates correct, executable code without imports. Within LangChain, it can be accessed via the HuggingFaceHub integration:
from langchain import HuggingFaceHub
llm = HuggingFaceHub(
task="text-generation",
repo_id="HuggingFaceH4/starchat-alpha",
model_kwargs={
"temperature": 0.5,
"max_length": 1000
}
)
print(llm(text))
As of August 2023, this integration can suffer from timeouts, so it is not used further here.
Other models: Llama 2 and local pipelines
Although Llama 2 achieves only ~29% pass@1 on HumanEval, it performs well on simple coding tasks when used via HuggingFace Chat.

Local models can also be used. For example, CodeGen (Salesforce) can be run via a HuggingFace pipeline:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
checkpoint = "Salesforce/codegen-350M-mono"
model = AutoModelForCausalLM.from_pretrained(checkpoint)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
pipe = pipeline(
task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=500
)
And invoked as:
completion = pipe(text)
print(completion[0]["generated_text"])
Or wrapped in LangChain:
from langchain import HuggingFacePipeline
llm = HuggingFacePipeline(pipeline=pipe)
llm(text)
CodeGen 350M achieves 12.76% pass@1 on HumanEval, while newer 6B-parameter versions reach over 26%. Other small but notable models include Microsoft’s CodeBERT, trained across multiple languages.
These completion-focused models are not instruction-tuned, but they can still be used for code generation, embeddings, and integration into agents. Instruction-tuned models, by contrast, are better suited for interactive assistance such as explaining code, documenting it, or translating between languages.
Takeaway
The approach shown here is intentionally simple. More advanced strategies—such as sampling multiple candidates and selecting the best—can significantly improve results, as shown in recent research. In the next section, we extend this workflow by introducing a feedback loop that runs, validates, and iteratively improves generated code.
Automated software development
We now move from code generation to a fully automated agent that writes code, executes it, and iteratively fixes errors based on feedback.
LangChain provides several tools for code execution, such as LLMMathChain for solving math problems and BashChain for running shell commands. While these tools are primarily designed for problem solving with code, they can also be combined into feedback loops that resemble software development.
A simple example uses a Zero-Shot ReAct agent with a Python REPL:
from langchain.llms.openai import OpenAI
from langchain.agents import load_tools, initialize_agent, AgentType
llm = OpenAI()
tools = load_tools(["python_repl"])
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
result = agent("What are the prime numbers until 20?")
print(result)
The agent decomposes the task, writes helper functions, executes them in Python, and returns the correct result. While effective, this approach does not directly address challenges central to real software development, such as modularity, abstractions, and maintainability.
Agent-based approaches
More advanced systems tackle this by simulating software teams. MetaGPT, for example, represents different organizational roles as agents:
from metagpt.software_company import SoftwareCompany
from metagpt.roles import ProjectManager, ProductManager, Architect, Engineer
async def startup(idea: str, investment: float = 3.0, n_round: int = 5):
company = SoftwareCompany()
company.hire([ProductManager(), Architect(), ProjectManager(), Engineer()])
company.invest(investment)
company.start_project(idea)
await company.run(n_round=n_round)
Other notable projects include AutoGPT, BabyGPT, Code-It, and GPT-Engineer, which rely on planning and feedback loops. Many of these systems struggle with instability, infinite loops, or execution failures.
Planning and execution with LangChain
LangChain supports similar workflows through constructs such as PlanAndExecute, ZeroShotAgent, and BabyAGI. Using PlanAndExecute, we can define an agent that plans steps and executes them iteratively:
agent_executor.run("Write a tetris game in python!")
To guide code generation, we define a developer-style prompt:
DEV_PROMPT = (
"You are a software engineer who writes Python code given tasks or objectives. "
"Come up with a python code for this task: {task} "
"Please use PEP8 syntax and comments!"
)
The model is configured with a long context window and low temperature to improve coherence and reduce randomness. However, code generation alone is insufficient—we also need execution, validation, and error handling.
Execution and feedback loop
This is handled by wrapping code generation and execution into a tool:
class PythonDeveloper():
def write_code(self, task: str) -> str:
return self.llm_chain.run(task)
def run(self, task: str) -> str:
code = self.write_code(task)
try:
return self.execute_code(code, "main.py")
except Exception as ex:
return str(ex)
The generated code is compiled and executed in an isolated directory, with output captured for feedback. While error handling is simplified here, the full implementation distinguishes between common failures, including:
ModuleNotFoundError(missing dependencies)NameError(undefined variables)SyntaxError(invalid code)FileNotFoundError(missing assets)SystemExit(runtime crashes)
Some errors trigger automated fixes, such as installing missing packages or refining prompts with stricter constraints.
Tool augmentation
Additional tools improve robustness. For example, adding a search tool helps ensure the agent understands the task domain:
tools = [
codetool,
Tool(
name="DDGSearch",
func=ddg_search.run,
description="Research background information about the objective."
)
]
This prevents common failures, such as implementing the wrong game mechanics. With repeated planning, searching, coding, and execution, the agent eventually produces runnable code. For the Tetris task, the final output launches a pygame window:
import pygame
import sys
pygame.init()
window = pygame.display.set_mode((800, 600))
pygame.display.set_caption('My Game')
while True:
for event in pygame.event.get():
if event.type == pygame.QUIT:
pygame.quit()
sys.exit()
window.fill((255, 255, 255))
pygame.display.update()
While syntactically correct, this result is far from a complete Tetris implementation. The agent succeeds at bootstrapping a project but struggles with higher-level design and completeness.
Discussion
This automated approach is still experimental. The full implementation is fewer than 400 lines of Python and easy to debug thanks to detailed logging of plans, searches, code, and errors. However, better results may come from:
- Breaking functionality into reusable functions
- Maintaining shared state across generations
- Test-driven development
- Human-in-the-loop feedback instead of full autonomy
Security is another concern. Executing generated code requires sandboxing; tools such as RestrictedPython, codebox-api, or directory-level sandboxes should be used in production settings.
Summary
This chapter explored the use of large language models (LLMs) for source code and their role in software development. We examined how LLMs can support developers primarily as coding assistants and reviewed several models through practical code-generation examples.
Using naïve generation approaches, we evaluated the results qualitatively and found that, while outputs often appear plausible, they frequently contain bugs, incomplete logic, or fail to meet task requirements. This poses particular risks for beginners and raises concerns around safety, correctness, and reliability.
Building on earlier chapters, we revisited the idea of LLMs as goal-driven agents interacting with external environments. In the context of programming, feedback can come from compiler errors, runtime execution, automated tests, or human review. Incorporating such feedback loops is essential for moving beyond superficial code generation toward more robust systems.
With these foundations in place, the chapter highlights both the potential and the current limitations of LLMs in software development—and sets the stage for reflecting on the key takeaways from this discussion.