
Large Language Models (LLMs) such as GPT-4 excel at generating human-like text, but using them purely through APIs has clear limits. Their real potential emerges when they are combined with external data sources, tools, and reasoning systems. This chapter introduces LangChain as a framework that overcomes these limitations and enables more powerful, context-aware language applications.
We begin by examining core challenges of standalone LLMs—such as outdated knowledge, flawed reasoning, and inability to act—and show how LangChain addresses them through modular components and integrations. The goal is to demonstrate how LangChain enables dynamic, data-aware applications that go far beyond basic API calls. Key concepts such as chains, action planning, and memory are also introduced.
Table of Contents
Going beyond stochastic parrots
LLMs are widely used for content generation, classification, and summarization due to their fluency in natural language. However, this fluency masks fundamental weaknesses. The term stochastic parrots, introduced by Bender et al. in On the Dangers of Stochastic Parrots (2021), describes models that mimic language patterns without true understanding or grounding in the real world.
Scaling data and compute alone does not grant reasoning or common sense. LLMs struggle with issues such as the compositionality gap (Press et al., 2023), limiting their ability to connect facts or adapt to novel situations. Addressing these gaps requires augmentation techniques like prompting strategies, chain-of-thought reasoning, retrieval grounding, and external tools. Without such support, LLMs remain eloquent but shallow systems.
What are the limitations of LLMs?
Despite their strengths, LLMs face several well-known constraints:
- Outdated knowledge: Models are limited to their training data.
- Inability to take action: No native support for searches, calculations, or API calls.
- Lack of context: Difficulty maintaining conversational or task context.
- Hallucinations: Confident but incorrect or irrelevant outputs.
- Biases: Reflections of biases present in training data.
- Lack of transparency: Opaque internal decision-making.
These issues become critical in real-world applications. LLMs cannot access current events, retrieve live data, or perform computations. For example, while an LLM may explain financial theory, it cannot retrieve market data or compute metrics without external tooling. Similarly, reasoning across multiple facts (multi-hop reasoning) often fails without explicit structure.
Illustrating LLM limitations
A common example is knowledge cut-off. When asked about LangChain in the ChatGPT interface, the model may acknowledge missing up-to-date information:
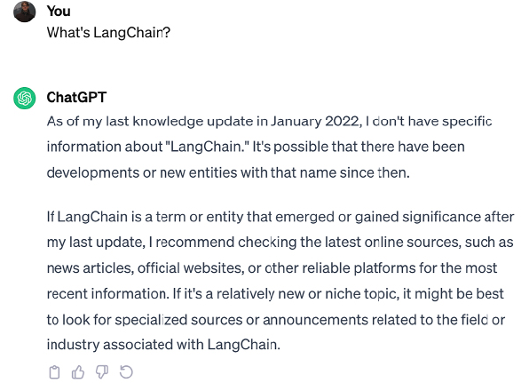
In other cases, models hallucinate. When queried via the OpenAI Playground, GPT-3.5 referenced an unrelated blockchain project named LangChain:

LLMs also struggle with arithmetic and logic. In a simple math example:

The model answers one question correctly but fails another. A calculator confirms the correct result:

This illustrates that LLMs do not reliably perform computation unless explicitly augmented with tools.
How can we mitigate LLM limitations?
Common mitigation techniques include:
- Retrieval augmentation: Injecting external, up-to-date knowledge.
- Chaining: Sequencing reasoning steps and actions.
- Prompt engineering: Providing structured context and guidance.
- Monitoring and filtering:
- Automated filters (blocklists, classifiers)
- Constitutional principles
- Human review
- Memory: Persisting conversational context.
- Fine-tuning: Adapting models to specific domains and values.
These methods collectively bridge reasoning gaps, reduce hallucinations, and improve reliability. Prompting supplies structure, chaining enables inference, retrieval adds facts, and monitoring ensures safe operation. Frameworks like LangChain package these techniques into a coherent, developer-friendly system.
What is an LLM app?
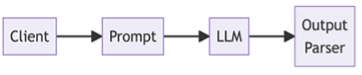
An LLM app combines language models with tools, data, and reasoning pipelines to solve real tasks. While traditional applications follow layered architectures:

LLM apps center language understanding as a core capability. Typical components include:
- Client layer for user input
- Prompt engineering layer
- LLM backend
- Output parsing layer
- Optional integrations (APIs, databases, tools)
In simple cases, this reduces to just the client, prompt, and model:
More advanced apps integrate retrieval, function calls, and reasoning algorithms:
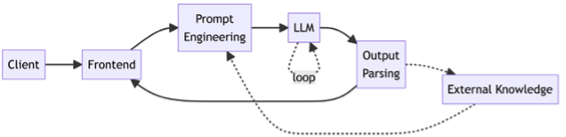
Retrieval-augmented generation (RAG), function calling, SQL querying, and chain-of-thought reasoning allow LLMs to act, reason, and stay current without modifying the base model.
Why LLM apps matter
LLM apps enable:
- Human-like language handling without hardcoded rules
- Personalized, contextual responses
- Multi-step reasoning
- Real-time, data-driven outputs
They reduce the need to anticipate every interaction in code and unlock new application classes. However, responsible design is essential: privacy, moderation, and bias mitigation must be built into both input handling and output parsing.
Common LLM app use cases include:
- Chatbots and virtual assistants
- Intelligent search
- Automated content generation
- Question answering
- Sentiment analysis
- Text summarization
- Data analysis
- Code generation
Why LangChain?
The real power of LLMs lies in integration, not isolation. LangChain provides a structured framework for combining LLMs with memory, tools, data sources, and reasoning pipelines. By addressing core LLM limitations, LangChain enables developers to build robust, context-aware, and action-capable language applications that would otherwise be impractical.
What is LangChain?
Created in 2022 by Harrison Chase, LangChain is an open-source Python framework for building LLM-powered applications. It provides modular components that connect language models with external data sources, tools, and services. The project has attracted significant venture funding from firms such as Sequoia Capital and Benchmark.
LangChain simplifies the development of advanced LLM applications by offering reusable building blocks and pre-assembled chains. Its modular architecture abstracts LLMs and external services behind a unified interface, allowing developers to compose complex workflows with minimal boilerplate.
Building production-ready LLM apps involves challenges such as prompt engineering, bias mitigation, integration with external data, and deployment. LangChain reduces this learning curve through composable abstractions and opinionated patterns.
Beyond simple API calls, LangChain enables conversational context, persistence, and decision-making through agents and memory. This supports use cases such as chatbots, data retrieval, and tool-augmented reasoning.
In particular, LangChain’s support for chains, agents, tools, and memory allows applications to interact with their environment, store and reuse information, and follow action plans. Access to external data and persistent memory helps reduce hallucinations and improves reliability.
Key benefits of LangChain
- Modular architecture for flexible LLM integrations
- Chaining multiple services beyond standalone LLM calls
- Goal-driven agent workflows
- Memory and persistence for stateful applications
- Open-source ecosystem and community support
LangChain is written in Python, with companion projects such as LangChain.js (TypeScript) and the early-stage LangChain.rb for Ruby. This tutorial focuses on the Python implementation.
While documentation, courses, and community resources accelerate onboarding, applying LLMs effectively still requires time and experience. Active community support exists through Discord, blogs, and meetups in cities such as San Francisco and London. A documentation chatbot, ChatLangChain, built with LangChain and FastAPI, is also available online.
LangChain has grown into a broad ecosystem with many integrations added weekly. A snapshot of supported integrations is shown below:
The LangChain ecosystem
- LangSmith: A companion platform for debugging, testing, and monitoring LLM applications. It provides execution traces, prompt and model evaluation, and usage analytics.
- LlamaHub: A library of data loaders and tools from the LlamaIndex community that simplifies connecting LLMs to diverse knowledge sources.
- LangChainHub: A central repository for sharing reusable artifacts such as prompts, chains, and agents, inspired by Hugging Face Hub.
- LangFlow and Flowise: Visual UIs for building LangChain pipelines via drag-and-drop flowcharts, enabling rapid experimentation and prototyping.
An example Flowise pipeline is shown below:

LangChain and LangFlow can be deployed locally (for example, with Chainlit) or on cloud platforms such as Google Cloud. The langchain-serve library enables one-command deployment on Jina AI as LLM-apps-as-a-service.
Although still relatively young, LangChain enables sophisticated LLM applications through its combination of memory, chaining, and agents. It abstracts away much of the complexity inherent in LLM application development, setting the stage for a deeper exploration of how LangChain works and how its components fit together.
Exploring key components of LangChain
LangChain enables sophisticated LLM applications through four core components: chains, agents, memory, and tools. Together, they allow developers to combine language models with external data, reasoning, and actions. This section focuses on what these components are used for, rather than implementation details, providing the conceptual foundation needed to architect LangChain systems.
What are chains?
Chains are LangChain’s core abstraction for composing reusable pipelines. A chain is a sequence of component calls—often multiple LLM invocations and tools—assembled to perform a task. Chains can include other chains, enabling hierarchical composition.
The simplest example is a PromptTemplate, which formats input before passing it to an LLM. More advanced chains integrate tools such as:
LLMMathfor numerical reasoningSQLDatabaseChainfor querying databases
These are often called utility chains, as they combine language models with specialized tools.
Chains can also enforce policies and safeguards:
OpenAIModerationChainensures outputs comply with moderation rulesConstitutionalChainenforces ethical or legal principles
To reduce hallucinations, LLMCheckerChain applies self-reflection to verify assumptions and statements. Research such as SELF-REFINE (May 2023) shows this approach can improve task performance by ~20%.
Some chains make routing decisions. For example, a RouterChain dynamically selects which prompt, retriever, or index to use based on the input.
Benefits of chains
- Modularity: Logic split into reusable components
- Composability: Flexible sequencing of steps
- Readability: Clear, inspectable pipelines
- Maintainability: Easy to modify or extend
- Reusability: Configurable, repeatable workflows
- Tool integration: Seamless access to APIs, databases, and models
- Productivity: Rapid prototyping of complex logic
Well-designed chains break workflows into single-responsibility steps, remain stateless, support configuration, and include error handling, logging, and monitoring via callbacks.
What are agents?
Agents enable goal-driven, interactive behavior. An agent is an autonomous entity that observes inputs, decides what to do, executes actions, and iterates until a goal is reached.
Chains and agents are closely related:
- Chains define reusable logic pipelines
- Agents orchestrate chains to pursue goals
Agents use LLMs as reasoning engines. Given user input, available tools, and past steps, the model selects the next action or produces a final answer.
Tools are functions the agent can invoke to act in the real world. Clear tool definitions are critical for effective agent behavior. The agent executor manages the reasoning loop, tool execution, error handling, and logging.
Benefits of agents
- Goal-oriented execution
- Dynamic adaptation to new observations
- Statefulness via memory
- Robustness through retries and fallbacks
- Composition of reusable chains
Agents shine in multi-step workflows and interactive systems like chatbots. For example, instead of attempting math internally, an agent can delegate calculations to a Python interpreter.
However, both chains and agents are stateless by default. Persisting context requires memory.
What is memory?
In LangChain, memory enables state to persist across executions. This is essential for conversational and long-running applications.
Memory allows:
- Consistent conversations using chat history
- Agents to retain facts, relationships, and goals
- Reduced LLM calls by avoiding repeated context
- Lower latency and API costs
LangChain provides a standard memory interface with multiple implementations, including:
ConversationBufferMemory: stores full chat history (higher cost)ConversationBufferWindowMemory: keeps recent messages onlyConversationKGMemory: summarizes interactions as a knowledge graphEntityMemory: persists structured facts in databases
Storage backends
LangChain integrates with:
- SQL databases (Postgres, SQLite)
- NoSQL systems (MongoDB, Cassandra)
- Redis for fast in-memory storage
- Managed services like DynamoDB
Specialized memory servers such as Remembrall and Motörhead further optimize conversational context. Choosing the right memory strategy depends on scale, persistence needs, and cost constraints.
What are tools?
Tools connect agents and chains to external systems such as APIs, databases, and services. Toolkits group related tools, and custom tools can be easily defined.
Examples include:
- Translator: enables multilingual understanding
- Calculator: ensures accurate math operations
- Maps: location, routing, and POI lookup
- Weather: real-time forecasts
- Stocks: market data via APIs like Alpha Vantage
- Slides: slide generation via
python-pptx - Table processing: pandas-based analysis and visualization
- Knowledge graphs: SPARQL queries and entity lookup
- Search engines: real-time web retrieval
- Wikipedia: entity search and disambiguation
- Online shopping: product search and selection
Additional tools include image generation, 3D modeling, chemistry APIs, and database query tools. By integrating tools, LLMs move beyond text generation into real-world action and analysis.
How does LangChain work?
LangChain simplifies building advanced LLM applications by providing modular components that connect language models with data sources, tools, and reasoning layers. These components are organized into modules that range from basic model interaction to advanced reasoning, retrieval, and persistence.
At its core, LangChain enables developers to assemble pipelines (chains) that sequence actions such as:
- Loading documents
- Creating embeddings for retrieval
- Querying LLMs
- Parsing outputs
- Writing to memory
Chains are aligned with application goals, while agents use chains dynamically to plan actions, respond to user input, and persist context across interactions.
Core LangChain modules
LangChain provides a broad set of interoperable modules, including:
- LLMs and chat models: Standardized interfaces for querying models such as GPT-style chat and completion models, with support for async, streaming, and batch requests.
- Document loaders: Ingest data from files, webpages, APIs, videos, and other sources into structured documents with text and metadata.
- Document transformers: Split, filter, combine, translate, or otherwise adapt documents for model consumption.
- Text embeddings: Convert text into vector representations for semantic similarity search.
- Vector stores: Index and store embeddings for efficient retrieval at scale.
- Retrievers: Abstract interfaces that return relevant documents for a given query, often backed by vector stores.
- Tools: Interfaces that allow agents to interact with external systems and APIs.
- Agents: Goal-driven controllers that use LLMs to select actions based on observations.
- Toolkits: Bundled sets of tools sharing common resources (for example, databases).
- Memory: Persistent storage of conversational or task state across executions.
- Callbacks: Hooks for logging, monitoring, tracing, streaming, and debugging chains.
Together, these modules enable the construction of efficient, reliable, and production-ready LLM applications.
Model integration and prompts
LangChain does not provide its own models but offers LLM wrappers that integrate with providers such as OpenAI, Hugging Face, Azure, and Anthropic. A standardized interface makes it easy to swap models for cost, performance, or energy efficiency reasons.
A foundational abstraction is the prompt. Prompt templates encapsulate instructions, examples, and input variables, making prompt engineering repeatable and reusable. LangChain includes a large collection of tested prompt templates, and supports systematic prompt optimization.
Data ingestion and transformation
Document loaders ingest structured and unstructured data (PDF, HTML, DOCX, JSON, CSV, and more). Document transformers then prepare this data for LLM use through chunking, filtering, translation, and enrichment.
These components are essential for retrieval-augmented generation and enable applications to ground model outputs in external knowledge.
Embeddings, vector stores, and retrieval
Embedding models convert text into vectors that capture semantic meaning. These vectors enable similarity-based search and retrieval. For large documents, content is chunked, embedded, and stored in vector stores, allowing relevant pieces to be retrieved efficiently.
LangChain supports a wide range of vector store integrations, including:
- Faiss, Annoy, and scikit-learn
- Chroma, Pinecone, and MongoDB Atlas Vector Search
- Cassandra, Elasticsearch, PGVector, and many others
These tools significantly improve performance for tasks such as question answering, summarization, and knowledge-grounded chat.
Putting it together
LangChain’s modular design allows developers to mix and match components into chains and agents tailored to specific use cases. While later chapters explore concrete patterns and implementations, LangChain’s documentation and API references provide comprehensive coverage of available modules and examples:
- LangChain API reference
- LangChain use case documentation
Although alternative frameworks exist, LangChain stands out as one of the most feature-rich and widely adopted solutions for building complex, production-ready LLM applications.
Comparing LangChain with other frameworks
A growing number of frameworks aim to simplify building LLM-powered applications by combining generative models with tools, retrieval, and orchestration. Several open-source libraries now address different aspects of this problem space.
The following chart compares the popularity of major Python-based frameworks over time, based on GitHub star history:

Among the compared projects, Haystack is the oldest, originating in early 2020, and remains the least popular by GitHub stars. LangChain, LlamaIndex (formerly GPTIndex), and SuperAGI emerged in late 2022 or early 2023. While all have seen adoption, LangChain has grown the fastest and most consistently. AutoGen, a newer framework from Microsoft, has also attracted early interest.
Each framework emphasizes different strengths:
- LlamaIndex focuses primarily on advanced retrieval and data indexing rather than full LLM application orchestration.
- Haystack specializes in large-scale search and retrieval systems, with components optimized for retrievers, readers, and semantic indexing.
- LangChain emphasizes chaining, agents, and tool integration, making it well suited for complex business logic, prompt optimization, and context-aware reasoning.
- SuperAGI offers agent-based workflows and a marketplace for tools and agents, but its ecosystem and community support are smaller than LangChain’s.
- AutoGen introduces conversational, multi-agent workflows, enabling automated coordination between LLMs, humans, and tools through structured chat interactions.
Frameworks such as AutoGPT and similar recursive task-decomposition systems are excluded here due to limited reasoning robustness and frequent looping behavior. Libraries focused narrowly on prompt engineering, such as Promptify, are also omitted.
Beyond Python, LLM frameworks exist in other languages. For example, Dust, written in Rust, emphasizes LLM application design and deployment. Regardless of language, frameworks like LangChain aim to reduce complexity by providing guardrails, abstractions, and reusable components. However, foundational understanding remains essential to avoid common pitfalls and build responsible systems.
Conclusion
LLMs generate fluent language but face limitations in reasoning, real-world knowledge, and actionability. LangChain addresses these gaps by providing modular building blocks—such as chains, agents, memory, and tools—that enable developers to build sophisticated, context-aware LLM applications.
Chains sequence calls to models, databases, and APIs to support multi-step workflows. Agents orchestrate chains to pursue goals dynamically. Memory persists context across executions, enabling stateful interactions. Together, these components transform isolated LLM calls into complete, extensible applications.
In the next chapters, we build on these foundations to develop real-world systems, including conversational agents that combine LLMs with knowledge bases and advanced reasoning. With LangChain, developers can unlock the full potential of LLMs and begin building the next generation of AI-powered software.