
Large Language Models offer incredible opportunities for building innovative applications, but they also come with significant limitations. The key to success isn’t avoiding these constraints, but designing user experiences that navigate them effectively—sometimes even turning limitations into advantages.
The Fundamental Trade-off: Agency vs. Reliability
In Chapter 5, we introduced the central tension in LLM application design: balancing agency (the model’s ability to act autonomously) with reliability (the trustworthiness of its outputs). More agency can create more capable applications, but unchecked autonomy can lead to undesirable or unpredictable behavior.
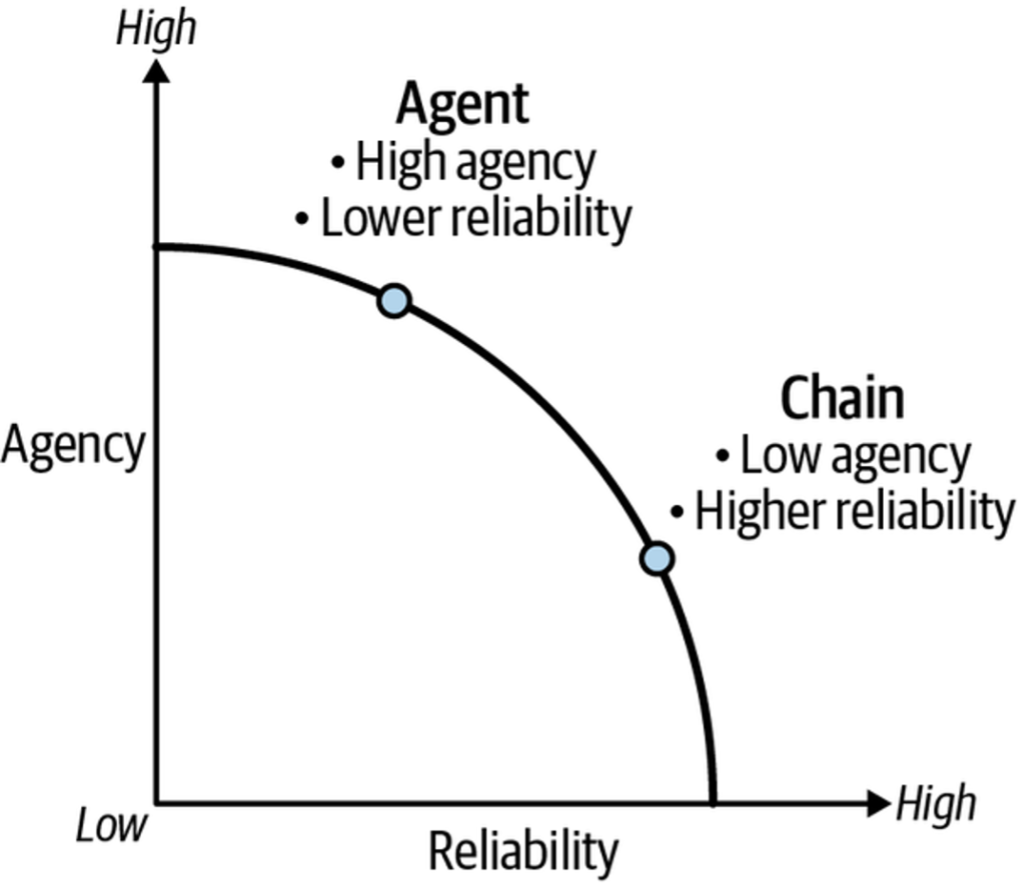
Think of this as a frontier where optimal LLM architectures exist. Different applications will find their sweet spot at different points along this curve. A chain architecture might offer high reliability but limited agency, while an Agent-based system might prioritize autonomy at the expense of consistent reliability.
Beyond Agency and Reliability: Additional Design Objectives
When designing your LLM application, consider these crucial objectives:
- Latency: Minimizing the time to deliver final answers
- Autonomy: Reducing the need for human intervention
- Variance: Decreasing differences between multiple invocations
These objectives often work against each other. Higher reliability might mean longer latency or reduced autonomy. Achieving zero latency might mean your application doesn’t do anything at all.
Shifting the Frontier: Techniques for Better Applications
The goal is to shift the entire frontier outward—achieving more agency without sacrificing reliability, or increasing reliability without losing autonomy. Here are key techniques to accomplish this:
1. Streaming/Intermediate Output
Longer processing times become acceptable when users receive progress updates or partial results along the way.
2. Structured Output
Predefined output formats ensure consistency and make LLM responses more predictable and usable for downstream applications.
3. Human-in-the-Loop
High-agency systems benefit from human oversight mechanisms like interruption, approval, or rollback capabilities.
4. Managing Concurrent Input
Long LLM response times create challenges when users send new inputs before processing completes—systems need to handle this gracefully.
Implementing Structured Output with LLMs
Structured output is essential when you need consistent formatting for downstream processing or want to reduce output variance.
Three Approaches to Structured Output
1. Prompting
Simply ask the LLM to return output in a specific format (JSON, XML, CSV, etc.).
Advantage: Works with any LLM
Limitation: Doesn’t guarantee compliance
2. Tool Calling
Use LLMs fine-tuned to select from predefined output schemas with names, descriptions, and format definitions (typically using JSONSchema).
3. JSON Mode
Some LLMs offer dedicated JSON modes that enforce valid JSON output structures.
Practical Implementation with Pydantic and LangChain
from pydantic import BaseModel, Field
class Joke(BaseModel):
setup: str = Field(description="The setup of the joke")
punchline: str = Field(description="The punchline to the joke")
# Configure the model for structured output
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
structured_model = model.with(Joke)
# Generate structured output
output = structured_model.invoke("Tell me a joke about cats")Resulting JSON Schema:
{
"setup": "Why don't cats play poker in the wild?",
"punchline": "Too many cheetahs."
}Note: Lower temperature settings minimize invalid outputs. If the LLM produces non-conforming output, you’ll receive a validation error rather than incorrect data.
Intermediate Output and Human Oversight with LangGraph
Streaming Intermediate Results
LangGraph can generate intermediate outputs that reduce perceived latency:
input_data = {
"messages": ["How old was the 30th president of the United States when he died?"]
}
for update in graph.stream(input_data, stream='updates'):
print(update) # Receive output as each node completesStreaming Modes:
- Updates: Output from each completed node
- Values: Entire current graph state after each node
- Debug: Detailed execution events
Human-in-the-Loop Implementation
Maintain oversight with interrupt and resume capabilities:
import asyncio
event = asyncio.Event()
input_data = {
"messages": ["How old was the 30th president of the United States when he died?"]
}
async with graph.astream(input_data) as stream:
async for chunk in stream:
if event.is_set():
break
print(chunk)
# Trigger interruption elsewhere in your application
event.set()Chapter Summary
This chapter explored the fundamental agency versus reliability trade-off in LLM applications and practical strategies to optimize this balance:
- Structured Outputs: Increase predictability and consistency
- Streaming/Intermediate Output: Manage latency in agency-focused applications
- Human-in-the-Loop Controls: Provide oversight for high-agency architectures
- Concurrent Input Handling: Address challenges created by LLM processing delays
The concepts discussed here parallel principles in other fields:
- Finance: The efficient frontier in portfolio optimization
- Economics: The production-possibility frontier
- Engineering: The Pareto front
In the next chapter, you’ll learn how to deploy your AI application into production, moving from development concepts to real-world implementation.