
Over the past decade, deep learning has advanced rapidly, enabling machines to process and generate unstructured data such as text, images, and video. These advances—especially large language models (LLMs)—have fueled widespread excitement across media and industry. AI is increasingly seen as a transformative force with the potential to reshape businesses, societies, and individual work.
This chapter introduces generative models and explains, at a high level, how techniques like neural networks, large datasets, and computational scale enable models to generate human-like content. Rather than covering every modality in depth, the goal is to demystify how generative AI works and prepare readers to evaluate both its opportunities and challenges.
Table of Contents
Let’s start with the terminology.
Introducing generative AI
Generative AI has gained significant attention due to its ability to produce text, images, and other creative content that often rivals human output. Beyond generation, these models support tasks such as semantic search, classification, and content manipulation—enabling automation and amplifying human creativity.
Generative AI refers to models that generate new content, in contrast to traditional predictive systems that only analyze existing data.
Benchmarks have been a major driver of progress. Figure 1 shows average LLM performance on the Massive Multitask Language Understanding (MMLU) benchmark, which measures knowledge and reasoning across domains such as mathematics, law, and computer science. The figure highlights rapid improvements in recent years, particularly across OpenAI’s publicly released models.

While these results should be interpreted cautiously—due to self-reporting and differences between zero-shot and five-shot evaluations—the gains between GPT-2, GPT-3, GPT-3.5, and GPT-4 are substantial. Five-shot prompting alone may account for roughly 20% of performance gains.
Key contributors to these improvements include:
- Scaling model parameters (from billions to trillions)
- Instruction tuning using human feedback
- Architectural refinements and more diverse training data
Although some models now outperform average human raters on certain benchmarks, they generally fall short of expert-level performance and still struggle on tasks like grade-school math (GSM8K).
Generative Pre-trained Transformer (GPT) models—such as GPT-4—exemplify recent progress. ChatGPT’s widespread adoption demonstrates how larger models enable more capable conversational agents, supporting use cases from customer support to programming and creative writing.
These models increasingly function as generalist assistants. For example, GPT-4 performs well across subjects including mathematics, economics, biology, and law (including the Uniform Bar Exam), positioning LLMs as valuable tools for knowledge work.
OpenAI, founded in 2015, has been central to these developments. Originally a nonprofit, it transitioned to a capped for-profit model in 2019 and formed a close partnership with Microsoft. Key contributions include OpenAI Gym, the GPT model family, and DALL·E for text-to-image generation.
Generative models have also advanced computer vision, improving tasks such as object detection, segmentation, and image captioning.
What are generative models?
In popular media, artificial intelligence is often used as an umbrella term. In practice, it helps to distinguish between related concepts:
- Artificial Intelligence (AI): Creating systems that reason, learn, and act autonomously
- Machine Learning (ML): Algorithms that learn patterns from data
- Deep Learning (DL): ML using deep neural networks
- Generative Models: Models that create new data resembling training data
- Language Models (LMs): Models that predict word sequences; large versions are LLMs
Unlike predictive models, generative models synthesize new data, enabling applications such as text, image, music, and video generation. They are also used to create synthetic training data when real data is scarce. For example, Microsoft’s phi-1 model was trained using AI-generated Python textbooks.
Common generative model categories
- Text-to-text: GPT-4, Claude, LLaMA 2
- Text-to-image: DALL·E 2, Stable Diffusion, Imagen
- Text-to-audio: AudioLM, MusicGen
- Text-to-video: Phenaki, Emu Video
- Text-to-speech: WaveNet, Tacotron
- Speech-to-text: Whisper
- Image-to-text: CLIP
- Image-to-image: Super-resolution, style transfer, inpainting
- Text-to-code: Codex, AlphaCode
Some models are multimodal. GPT-4V, released in 2023, accepts both text and images, enabling OCR and safer image captioning by routing visual input through text-based filters.
Text is a common input modality that can be transformed into images, audio, video, or code. While this tutorial focuses mainly on LLMs, text-to-image models are also discussed. Most of these systems rely on Transformer architectures trained via self-supervised learning.
Despite rapid progress, challenges remain, including data bias, evaluation difficulty, compute costs, misuse risks, and broader societal impacts.
Why now?
The public breakthrough of generative AI around 2022 resulted from several converging factors:
- Algorithmic progress
Backpropagation, improved optimizers, and advances in neural architectures laid the foundation. Transformers (2017) introduced attention mechanisms that significantly improved scalability and performance. - Hardware acceleration
GPUs—particularly through NVIDIA’s CUDA platform—dramatically reduced training time. Figure 2 shows the long-term decline in storage costs, making large-scale training economically feasible. - Model scaling
Larger models better capture linguistic structure. As models reached billions of parameters, new capabilities emerged, including creative writing, code generation, and open-ended reasoning. Lower perplexity generally correlates with better task performance. - Tooling and frameworks
Libraries such as PyTorch, TensorFlow, and Keras streamlined experimentation and deployment. - Data availability
The explosion of internet data enabled training on unprecedented volumes of text and images. - Benchmarks and community
Shared benchmarks such as ImageNet and MMLU helped standardize evaluation and accelerate progress.
Earlier generative approaches—autoencoders, VAEs, and GANs—were critical stepping stones, but Transformers and transfer learning enabled today’s large-scale models.

Understanding LLMs
Text generation models such as OpenAI’s GPT-4 can produce fluent, grammatically correct text across languages and formats. Their core purpose is to enable machines to understand and generate natural language, supporting tasks like content creation, translation, summarization, and text editing.
At a fundamental level, language modeling predicts the next word (or token) in a sequence based on prior context. Through this process, LLMs internalize grammar, syntax, and semantics, forming the backbone of modern NLP systems.
Central to this capability is representation learning—models learn internal representations directly from raw data rather than relying on hand-engineered features. Just as vision models learn edges and shapes from pixels, LLMs learn linguistic structure directly from text.
LLMs are widely used across domains, including:
- Question answering: Powering chatbots and virtual assistants for customer support and task automation
- Automatic summarization: Condensing long documents into concise summaries
- Sentiment analysis: Extracting opinions and emotions from text
- Topic modeling: Identifying latent themes across large document collections
- Semantic search: Improving relevance by understanding meaning rather than keywords
- Machine translation: Achieving near-commercial translation quality
Despite their strengths, LLMs still struggle with complex mathematical reasoning and logic. They generate the most probable response, which can lead to confident but incorrect outputs—commonly called hallucinations.
What is a GPT?
LLMs are deep neural networks based on the Transformer architecture and pre-trained on massive text corpora using self-supervised learning. Their ability to act as general-purpose “foundation models” enables reuse across many downstream tasks.
GPT models generate text autoregressively—predicting one token at a time—often producing responses indistinguishable from human writing. However, as OpenAI notes, they may sometimes generate plausible but incorrect answers.
The Transformer, introduced in Attention Is All You Need (Vaswani et al., 2017), relies on self-attention and feed-forward layers to model relationships between words regardless of distance. GPT models, introduced by OpenAI in 2018 (Improving Language Understanding by Generative Pre-Training), apply this architecture using a next-token prediction objective.
Training data and model scale have increased dramatically:
- GPT-1 (2018): ~1B words
- BERT (2018): ~3.3B words
- Modern LLMs: trillions of tokens
This growth is illustrated in Figure 3, which shows model size, training cost, and organizational ownership across major LLMs.

GPT models have evolved into multimodal foundation models, supporting image input (GPT-4V) and enabling related technologies such as diffusion-based text-to-image systems.
GPT-3, trained on ~300B tokens with 175B parameters, marked a turning point. GPT-4’s exact size is undisclosed, though estimates range from hundreds of billions to over a trillion parameters, with training costs reportedly exceeding $100M.
ChatGPT, released in November 2022, demonstrated the power of instruction tuning and human feedback (RLHF), delivering strong multi-turn dialogue and safety improvements. GPT-4 further improved performance and alignment through extended fine-tuning.
Other LLMs
Several non-OpenAI models have advanced the field:
- PaLM 2 (Google DeepMind): Smaller, more compute-efficient, with strong multilingual and reasoning performance
- LLaMA & LLaMA 2 (Meta): Open models up to 70B parameters that catalyzed an explosion of open-source LLMs
- Claude / Claude 2 (Anthropic): Strong GPT-4 competitor with up to 200K token context windows
- Mistral, Falcon, GPT-Neo, GPT-J: Open or semi-open alternatives enabling broader experimentation
While some open models approach closed-source systems on specific benchmarks, a significant performance gap remains at the very top end.
Major players
Training modern LLMs requires massive compute budgets—often $10M to $100M+—and specialized expertise. As shown in Figure 3, only a handful of organizations can train frontier models at scale, including OpenAI, Google, Meta, and Anthropic.
However, open-source releases like LLaMA have enabled smaller teams to achieve impressive results through fine-tuning and specialization, especially in coding and reasoning tasks.
How do GPT models work?
The Transformer architecture revolutionized NLP by enabling parallel processing and long-range dependency modeling. It uses an encoder–decoder structure with self-attention, feed-forward layers, residual connections, and normalization.
Figure 4 illustrates the Transformer architecture.
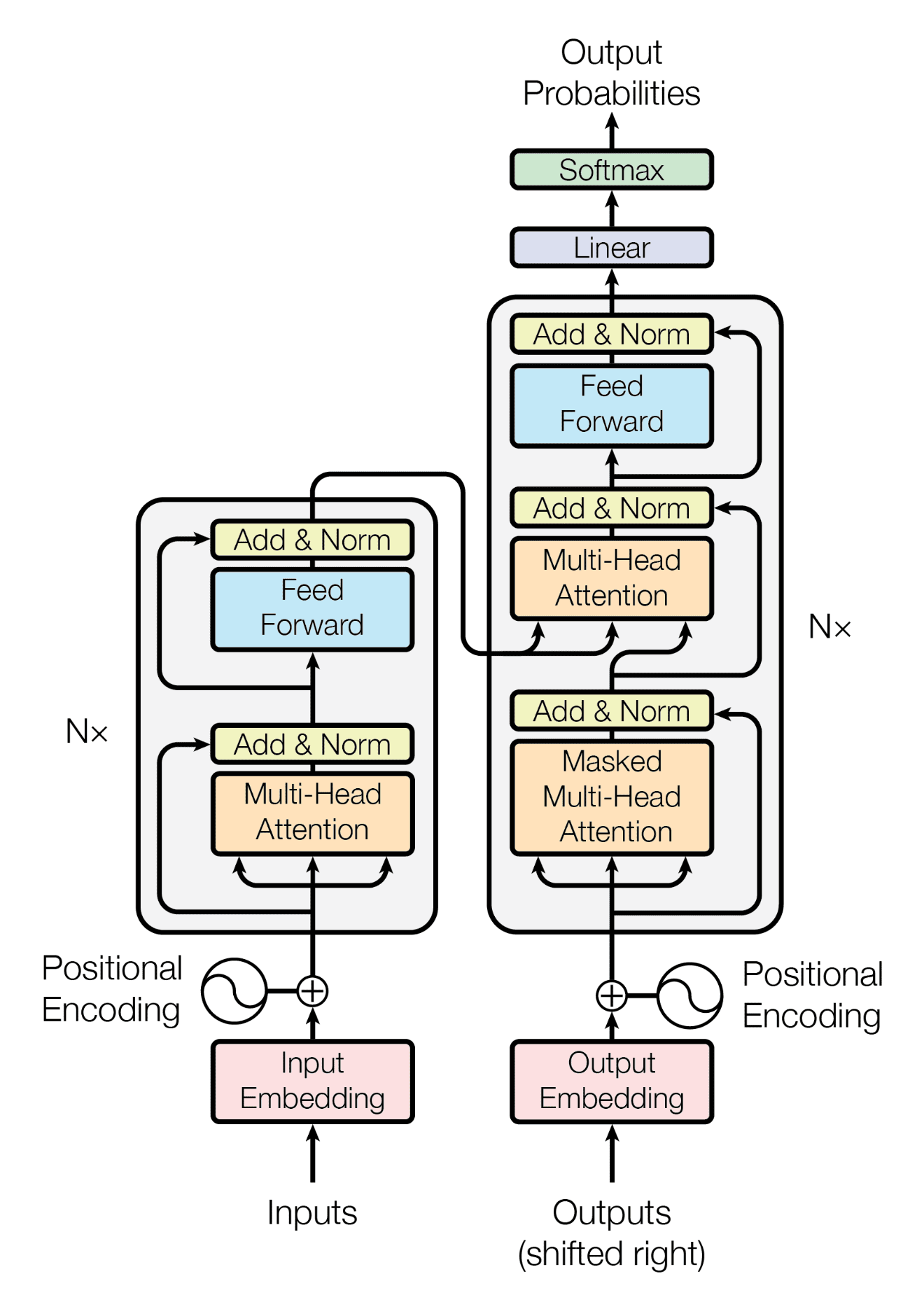
Key architectural features include:
- Positional encoding: Injects word order information
- Layer normalization: Stabilizes and accelerates training
- Multi-head attention: Captures different relational patterns in parallel
Transformers outperform recurrent models (e.g., LSTMs), especially on long contexts. Variants such as Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) improve inference speed and memory efficiency, enabling larger context windows.
Pre-training
LLMs are trained in two stages:
- Unsupervised pre-training: Learning general language representations
- Fine-tuning / alignment: Adapting models for tasks and safety
Objectives include:
- Masked Language Modeling (MLM) (e.g., BERT)
- Next-token prediction (e.g., GPT)
Training minimizes Negative Log-Likelihood (NLL) and Perplexity (PPL). Lower perplexity indicates better predictive performance and less “surprise” at the next token.
Tokenization
Before training, text is converted into tokens and mapped to numeric IDs:
- Tokens may be words, subwords, or characters
- Common tokenizers include BPE, WordPiece, and SentencePiece
Example:
“The quick brown fox jumps over the lazy dog!”
→ [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”, “!”]
Tokenizers are fitted once and frozen. Vocabulary sizes typically range from 30K–50K tokens. The context window limits how many tokens a model can process at once.
Scaling
As shown in Figure 3, LLMs have steadily grown larger. Scaling laws (Kaplan et al., 2020) show that performance improves predictably with:
- Model size
- Dataset size
- Compute budget
Optimal performance requires scaling all three together. Later work (Chinchilla, 2022) showed that many models were undertrained, while more recent research (Textbooks Are All You Need, 2023) demonstrated that smaller models trained on high-quality data can be competitive.
Whether continued scaling will yield further breakthroughs remains an open question.
Conditioning
After pre-training, models are adapted via:
- Fine-tuning: Supervised learning and RLHF for helpfulness and safety
- Prompting: Zero-shot or few-shot task conditioning via natural language instructions
These methods enable flexible task adaptation without retraining entire models.
How to try these models
Closed models (e.g., GPT-4) are accessible via APIs, while open-source LLMs can be run locally via platforms like Hugging Face. Users can fine-tune or deploy these models depending on their needs.
While this tutorial focuses on LLMs due to their broad applicability, text-to-image and other generative models also play an important role. The next section explores text-conditioned image generation, its progress, and remaining challenges.
What are text-to-image models?
Text-to-image models are a class of generative AI systems that create realistic images from textual descriptions. They are widely used in creative industries for advertising, design, prototyping, fashion, and visual effects.
Key applications include:
- Text-conditioned image generation: Creating images directly from prompts such as “a painting of a cat in a field of flowers.”
- Image inpainting: Filling in missing or corrupted regions for restoration or object removal.
- Image-to-image translation: Transforming images into new styles or domains (e.g., “make this photo look like a Monet painting”).
- Image recognition: Using large vision foundation models for classification and object detection.
Popular systems such as Midjourney, DALL·E 2, and Stable Diffusion are trained on large datasets of image–text pairs. Most modern systems rely on diffusion models, which generate images by gradually denoising random noise into a coherent visual representation.
Model architectures
Two main generative approaches have been used for text-to-image synthesis:
Generative Adversarial Networks (GANs)
GANs consist of a generator, which produces images from noise and text embeddings, and a discriminator, which judges whether images are real or synthetic. Through this adversarial process, GANs can produce highly realistic images, but training is often unstable and computationally expensive.
Diffusion models
Diffusion models have become the dominant approach due to improved stability and image quality. They work in two stages:
- Forward diffusion: Noise is gradually added to an image until it becomes unrecognizable.
- Reverse diffusion: The model learns to iteratively remove noise, reconstructing an image guided by the text prompt.
This process is analogous to reversing the diffusion of ink in water. An example of this denoising trajectory is shown in Figure 5, which visualizes selected steps from a 40-step generation process using Stable Diffusion.

How diffusion-based text-to-image models work
Models such as DALL·E 2, Imagen, and Stable Diffusion use a text encoder to convert prompts into embeddings. These embeddings condition a cascade of diffusion models that progressively refine a latent image representation.
A typical Stable Diffusion pipeline works as follows:
- Generate a random latent noise tensor.
- Use a U-Net to predict noise conditioned on the text embedding.
- Subtract predicted noise from the latent image.
- Repeat denoising for a fixed number of steps (e.g., 40).
- Decode the final latent representation into pixel space using a Variational Autoencoder (VAE).
Stable Diffusion
Stable Diffusion, developed by the CompVis group at LMU Munich, introduced latent diffusion models, significantly reducing training and inference costs compared to pixel-space diffusion. By operating in a lower-dimensional latent space, the model can run on consumer-grade GPUs while producing high-quality images.
Key components include:
- VAE: Compresses images into latent space and decodes final outputs.
- U-Net: Performs iterative denoising in latent space.
- Loss function: Typically Mean Squared Error (MSE), encouraging accurate noise prediction.
The model was trained on the LAION-5B dataset, containing billions of image–text pairs scraped from sources such as Common Crawl, Flickr, and DeviantArt. Stable Diffusion’s code and weights are released under the CreativeML OpenRAIL-M license, enabling broad reuse and commercialization.
Conditioning and control
Conditioning allows text-to-image models to be guided by prompts or additional inputs such as depth maps or outlines. Text embeddings are processed by a transformer and injected into the noise prediction process, steering image generation toward the desired outcome.
Small changes in prompts, samplers, or random seeds can yield dramatically different images—highlighting both the creative power and the instability of diffusion-based generation.
What can AI do in other domains?
Generative AI has expanded well beyond text and images, showing strong capabilities across audio, music, video, and 3D content.
In the audio domain, models can synthesize natural speech, generate original music, and even mimic a speaker’s voice and prosody. Speech-to-text systems—also known as Automatic Speech Recognition (ASR)—can transcribe spoken language with near human-level accuracy.
In video, generative models can create photorealistic clips from text prompts and perform advanced editing tasks such as object removal and scene modification. In 3D, models can reconstruct scenes from images and generate complex objects directly from textual descriptions.
Table 1 summarizes representative models across audio, video, and 3D domains, highlighting their architectures and capabilities, from music generation (Jukebox) and speech recognition (Whisper, USM) to text-to-video (Phenaki, Imagen Video) and text-to-3D generation (DreamFusion).
| Model | Organization | Year | Domain | Architecture | Performance |
| 3D-GQN | DeepMind | 2018 | 3D | Deep, iterative, latent variable density models | 3D scene generation from 2D images |
| Jukebox | OpenAI | 2020 | Music | VQ-VAE + transformer | High-fidelity music generation in different styles |
| Whisper | OpenAI | 2022 | Sound/speech | Transformer | Near human-level speech recognition |
| Imagen Video | 2022 | Video | Frozen text transformers + video diffusion models | High-definition video generation from text | |
| Phenaki | Google & UCL | 2022 | Video | Bidirectional masked transformer | Realistic video generation from text |
| TecoGAN | U. Munich | 2022 | Video | Temporal coherence module | High-quality, smooth video generation |
| DreamFusion | 2022 | 3D | NeRF + Diffusion | High-fidelity 3D object generation from text | |
| AudioLM | 2023 | Sound/speech | Tokenizer + transformer LM + detokenizer | High linguistic quality speech generation maintaining speaker’s identity | |
| AudioGen | Meta AI | 2023 | Sound/speech | Transformer + text guidance | High-quality conditional and unconditional audio generation |
| Universal Speech Model (USM) | 2023 | Sound/speech | Encoder-decoder transformer | State-of-the-art multilingual speech recognition |
Across these applications, progress is driven by advances in deep generative architectures—including GANs, diffusion models, and transformers—with major contributions from research labs at Google, OpenAI, Meta, and DeepMind.
Conclusion
Enabled by increased computing power and advances in deep neural networks, modern generative models capture the complexity of real-world data far more effectively than earlier approaches. In this chapter, we reviewed the evolution of deep learning and generative AI, focusing on LLMs and GPT models, the Transformer architecture, and diffusion-based image generation. We also surveyed applications beyond text and images, including sound, video, and 3D content.
The next chapter turns to tooling, introducing the LangChain framework and showing how it can be used to build, extend, and operationalize LLM-based applications.